Macchine a vettori di supporto

Le macchine a vettori di supporto (SVM, dall'inglese support-vector machines) sono dei modelli di apprendimento supervisionato associati ad algoritmi di apprendimento per la regressione e la classificazione. Dato un insieme di esempi per l'addestramento, ognuno dei quali etichettato con la classe di appartenenza fra le due possibili classi, un algoritmo di addestramento per le SVM costruisce un modello che assegna i nuovi esempi a una delle due classi, ottenendo quindi un classificatore lineare binario non probabilistico. Un modello SVM è una rappresentazione degli esempi come punti nello spazio, mappati in modo tale che gli esempi appartenenti alle due diverse categorie siano chiaramente separati da uno spazio il più possibile ampio. I nuovi esempi sono quindi mappati nello stesso spazio e la predizione della categoria alla quale appartengono viene fatta sulla base del lato nel quale ricade.
Oltre alla classificazione lineare è possibile fare uso delle SVM per svolgere efficacemente la classificazione non lineare utilizzando il metodo kernel, mappando implicitamente i loro ingressi in uno spazio delle caratteristiche multi-dimensionale.
Quando gli esempi non sono etichettati è impossibile addestrare in modo supervisionato e si rende necessario l'apprendimento non supervisionato: questo approccio cerca d'identificare i naturali gruppi in cui si raggruppano i dati, mappando successivamente i nuovi dati nei gruppi ottenuti. L'algoritmo di raggruppamento a vettori di supporto, creato da Hava Siegelmann e Vladimir N. Vapnik, applica le statistiche dei vettori di supporto, sviluppate negli algoritmi delle SVM, per classificare dati non etichettati, ed è uno degli algoritmi di raggruppamento maggiormente utilizzato nelle applicazioni industriali.
Motivazioni
Le macchine a vettori di supporto possono essere pensate come una tecnica alternativa per l'apprendimento di classificatori polinomiali, contrapposta alle tecniche classiche di addestramento delle reti neurali artificiali.
Le reti neurali a un solo strato hanno un algoritmo di apprendimento efficiente, ma sono utili soltanto nel caso di dati linearmente separabili. Viceversa, le reti neurali multistrato possono rappresentare funzioni non lineari, ma sono difficili d'addestrare a causa dell'alto numero di dimensioni dello spazio dei pesi e poiché le tecniche più diffuse, come la back-propagation, permettono di ottenere i pesi della rete risolvendo un problema di ottimizzazione non convesso e non vincolato che, di conseguenza, presenta un numero indeterminato di minimi locali.
La tecnica di addestramento SVM risolve entrambi i problemi: presenta un algoritmo efficiente ed è in grado di rappresentare funzioni non lineari complesse. I parametri caratteristici della rete sono ottenuti mediante la soluzione di un problema di programmazione quadratica convesso con vincoli di uguaglianza o di tipo box (in cui il valore del parametro deve essere mantenuto all'interno di un intervallo), che prevede un unico minimo globale.
Definizione
Formalmente, una macchina a vettori di supporto costruisce un iperpiano o un insieme di iperpiani in uno spazio a più dimensioni o a infinite dimensioni, il quale può essere usato per classificazione, regressione e altri scopi come il rilevamento delle anomalie. Intuitivamente una buona separazione si può ottenere dall'iperpiano che ha la distanza maggiore dal punto (del training set) più vicino di ognuna delle classi; in generale maggiore è il margine fra questi punti, minore è l'errore di generalizzazione commesso dal classificatore.
Mentre il problema originale può essere definito in uno spazio di finite dimensioni, spesso succede che gli insiemi da distinguere non siano linearmente separabili in quello spazio. Per questo motivo è stato proposto che lo spazio originale di dimensioni finite venisse mappato in uno spazio con un numero di dimensioni maggiore, rendendo presumibilmente più facile trovare una separazione in questo nuovo spazio. Per mantenere il carico computazionale accettabile, le mappature utilizzate dalle SVM sono fatte in modo tale che i prodotti scalari dei vettori delle coppie di punti in ingresso siano calcolati facilmente in termini delle variabili dello spazio originale, attraverso la loro definizione in termini di una funzione kernel scelta in base al problema da risolvere. Gli iperpiani in uno spazio multidimensionale sono definiti come l'insieme di punti il cui prodotto scalare con un vettore in quello spazio è costante, dove tale insieme di vettori è un insieme ortogonale (e quindi minimale) di vettori che definiscono un iperpiano. I vettori che definiscono gli iperpiani possono essere scelti come combinazioni lineari con parametri delle immagini dei vettori delle caratteristiche . Con tale scelta dell'iperpiano, i punti nello spazio delle caratteristiche che sono mappati nell'iperpiano sono definiti dalla relazione . Si noti che se diventa più piccolo al crescere di rispetto ad , ogni termine della somma misura il grado di vicinanza del punto di test al corrispondente punto di base . Si noti che l'insieme di punti mappato in un qualsiasi iperpiano può produrre un risultato piuttosto complicato, permettendo discriminazioni molto più complesse fra insiemi non completamente convessi nello spazio originario.






Storia
L'originale algoritmo SVM è stato inventato da Vladimir Vapnik e Aleksej Červonenkis nel 1963.
Nel 1992 Bernhard Boser, Isabelle Guyon e lo stesso Vapnik suggerirono un modo per creare un classificatore non lineare applicando il metodo kernel all'iperpiano con il massimo margine. Lo standard corrente che propone l'utilizzo di un margine leggero fu invece proposto da Corinna Cortes e Vapnik nel 1993 e pubblicato nel 1995.
SVM lineare
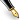 Questa sezione sull'argomento informatica è ancora vuota. Aiutaci a scriverla!
Questa sezione sull'argomento informatica è ancora vuota. Aiutaci a scriverla!Classificazione non lineare
Questa sezione sull'argomento informatica è ancora vuota. Aiutaci a scriverla!Calcolo del classificatore SVM
Questa sezione sull'argomento informatica è ancora vuota. Aiutaci a scriverla!Minimizzazione del rischio empirico
Estensioni
- Support vector clustering (SVC)
- SVM multiclasse
- SVM trasduttiva
- SVM strutturata
- SVM per regressione
Utilizzi
Alcune applicazioni per cui le SVM sono state utilizzate con successo sono:
- elaborazione del linguaggio naturale, ad esempio riconoscimento di cifre, campo in cui le SVM sono diventate in breve tempo competitive con i migliori metodi utilizzati
- identificazione di facce in immagini
- identificazione di pedoni
- classificazione di testi
- ricerca bioinformatica
- classificazione di immagini telerilevate
- rilevamento di spam nella posta elettronica
Implementazioni
I seguenti framework mettono a disposizione un'implementazione di SVM:
- LIBSVM[1]
- MATLAB
- SAS
- SVMlight
- Kernlab
- Orange
- scikit-learn
- Shogun
- Weka
- Shark
- JKernelMachines
- OpenCV
- R
- GPDT
- Gurobi
Note
- ^ https://www.csie.ntu.edu.tw/~cjlin/libsvm/
Bibliografia
- Stuart Russell e Peter Norvig, Intelligenza artificiale: un approccio moderno, Prentice Hall, 2003, ISBN 88-7192-229-8
Voci correlate
Altri progetti
Altri progetti
- Wikimedia Commons
 Wikimedia Commons contiene immagini o altri file sulla macchine a vettori di supporto
Wikimedia Commons contiene immagini o altri file sulla macchine a vettori di supporto
Collegamenti esterni
- (EN) www.kernel-machines.org (informazioni generali e materiale di ricerca)
- (EN) www.support-vector.net (novità, link e codice relativo alle macchine a vettori di supporto)
- (EN) Alcuni programmi SVM in diversi linguaggi, su csie.ntu.edu.tw.


| Controllo di autorità | LCCN (EN) sh2008009003 · GND (DE) 4505517-8 · BNF (FR) cb16627142b (data) · J9U (EN, HE) 987007539991605171 |
|---|
 Portale Informatica
Portale Informatica Portale Ingegneria
Portale Ingegneria Portale Statistica
Portale Statistica










